A piece of late news: the concurrency suite is back. And so is my little test on top of it.
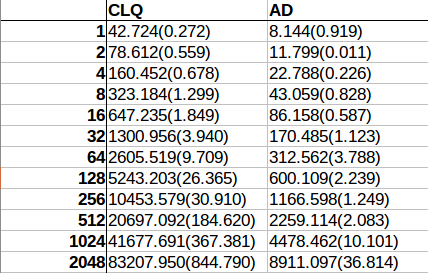
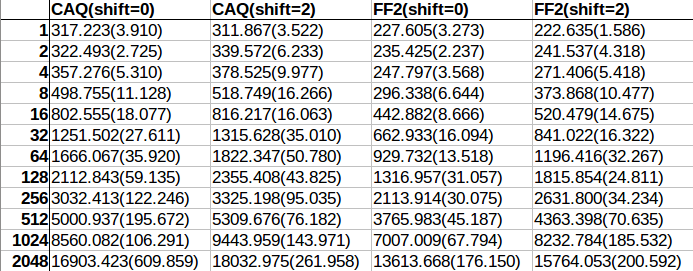
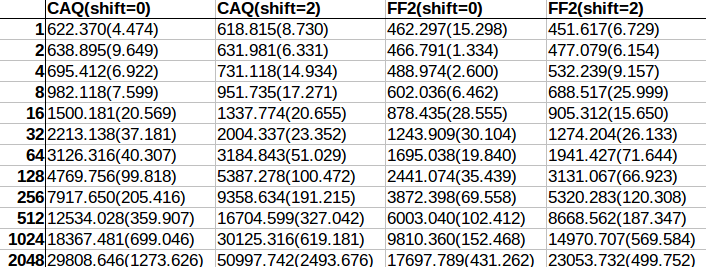
A few months ago I posted on yet another piece of joyful brilliance crafted by Master Shipilev, the java-concurrency-suite. I used the same framework to demonstrate some valid concerns regarding unaligned access to memory, remember children:
The java-concurrency-suite had to be removed from github, and the Master Inquisitor asked me to stop fucking around and remove my fork too, if it's not too much trouble... so I did.
Time flew by and at some point the powers that be decided the tool can return, but torture was too much of a strong word for those corporate types and so it has been rebranded JCStress. JC is nothing to do with the Jewish Community, as some might assume, it is the same Java Concurrency but now it's not torture (it's sanctioned after all), it's stress. Aleksey is simply stressing your JVM, he is not being excessively and creatively sadistic, that would be too much!
Following the article I had a short discussion with Mr T and Gil T with regards to unaligned access in the comments to Martin's blog post on off-heap tuple like storage. The full conversation is long, so I won't bore you, but the questions asked were:
A few months ago I posted on yet another piece of joyful brilliance crafted by Master Shipilev, the java-concurrency-suite. I used the same framework to demonstrate some valid concerns regarding unaligned access to memory, remember children:
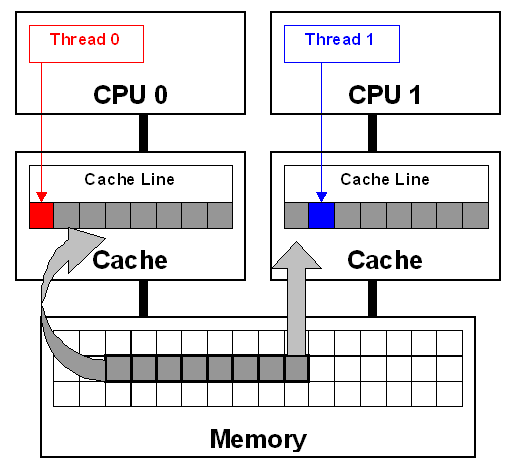
- Unaligned access is not atomic
- Unaligned access is potentially slow, in particular:
- On older processors
- If you cross the cache line
- Unaligned access can lead to SEG_FAULT on non-intel architectures, and the result of that might be severe performance hit or your process crashing...
The java-concurrency-suite had to be removed from github, and the Master Inquisitor asked me to stop fucking around and remove my fork too, if it's not too much trouble... so I did.
Time flew by and at some point the powers that be decided the tool can return, but torture was too much of a strong word for those corporate types and so it has been rebranded JCStress. JC is nothing to do with the Jewish Community, as some might assume, it is the same Java Concurrency but now it's not torture (it's sanctioned after all), it's stress. Aleksey is simply stressing your JVM, he is not being excessively and creatively sadistic, that would be too much!
Following the article I had a short discussion with Mr T and Gil T with regards to unaligned access in the comments to Martin's blog post on off-heap tuple like storage. The full conversation is long, so I won't bore you, but the questions asked were:
- Is unaligned access a performance only, or also a correctness issue?
- Are 'volatile' write/reads safer than normal writes/reads?
- Unaligned access is not atomic, and therefore can lead to the sort of trouble you will not usually experience in your programs (i.e half written long/int/short values). This is a problem even if you use memory barriers correctly. It adds a 'happened-badly' eventuality to the usual happens before/after reasoning and special care must be taken to not get slapped in the face with a telephone pole.
- Volatile read/writes are NOT special. In particular doing a CAS/putOrdered/volatile write to an unaligned location such that the value is written across the cache line is NOT ATOMIC (this statement is under further investigation. At the very least a volatile read is definitely not atomic. More on this issue to follow).